Unicode




Unicode (Evrensel Kod) Unicode Consortium organizasyonu tarafından geliştirilen ve her karaktere bir sayı değeri karşılığı atayan bir endüstri standardıdır. Sistemin amacı farklı karakter kodlama sistemlerinin birbiriyle tutarlı çalışmasını ve dünyadaki tüm yazım sistemlerinden metinlerin bilgisayar ortamında tek bir standart altında temsil edilebilmesini sağlamaktır. Evrensel Karakter Kümesi (UCS) olarak bilinen ISO/IEC 10646 standardı ise, her iki organizasyonun işbirliği ile aynı sayısal karşılıkları taşımaktadır. Unicode, son sürümü itibarıyla 129 farklı modern ve tarihî yazım sistemine ait 120.000'den fazla karakteri ve emoji gibi çeşitli sembol kümelerini kapsamaktadır.
Standardın içinde karakterler ve karakterlere atanmış sayı değerlerinin tablolaştırılmış hali, bu sayılarının kodlanmasıyla ilgili kurum tarafından önerilen standart kodlama sistemleri ve bunların yanı sıra eşdeğer karakterler, karakterin bileşenlerine ayrılış bilgileri, sıralama kuralı, büyük-küçük harf bilgisi, yazılış yönü bilgisi gibi karakterin ekranda doğru gösterilebilmesi için yazılımların ihtiyaç duyduğu ek bilgiler bulunmaktadır.[1] Haziran 2015 tarihi itibarıyla standardın en son sürümü olan Unicode 8.0 ile birlikte 7.716 yeni karakter eklemesi yapılmıştır[2]
Unicode kodlarından oluşan karakter dizilerini (metinleri) bilgisayarda verimli bir biçimde saklayabilmek amacıyla çeşitli karakter kodlamaları geliştirilmiştir. Bunlardan en bilinenleri UTF-8, UTF-16 ve artık kullanımdan kalkmış olan UCS-2'dir.
Unicode öncesi
Harflerin bilgisayar ortamında saklanması ve taşınması ile ilgili geliştirilen ilk sistem ASCII sistemi olmuştur. Bu sistemde Amerikan İngilizcesi alfabesinde bulunan harflerin her birine bir sayı atanmış ve harfler bilgisayar ortamında sayı olarak saklanmıştır. Harflerin kodlanması için 7 bitlik baytlar kullanılmıştır. 7 bit ile yazılabilen en büyük sayı 127'dir ve 128 adet sayı (0 ile 127 arası) temel noktalama işaretleri ve Amerikan İngilizcesi harflerini kodlamak için yeterli olmuştur. Örneğin a harfi ASCII kodlamasında on tabanında 97 sayısıyla eşleştirilmiştir. Harflerin eşleştirildiği bu sayılar daha sonra Unicode tarafından kod noktası olarak adlandırılacaktır.
ASCII kodlaması kullanılmaya başladıktan sonra Latin alfabesi kullanan Avrupa ülkelerinin alfabelerindeki ü, ö veya ç gibi harflerin de kodlanması ihtiyacı ortaya çıktığından Genişletilmiş ASCII denilen yeni bir sistem kullanılmıştır. Bu sistemde harfleri kodlamak için kullanılan yedi bite bir bit daha eklenerek 8 bitlik baytlar kullanılmış ve dolayısıyla kodlanabilecek harf sayısı 27 = 128'den 28 = 256'ya çıkarılmıştır. İlk çıkarılan genişletilmiş ASCII kümesi olan ISO 8859-1 (Latin-1 olarak da bilinir), Latin alfabesi kullanan Batı Avrupa dillerinin büyük çoğunluğunun harflerini karşılamaktadır. Daha sonra farklı dillerin alfabelerinde bulunan o dile özgü karakterler için farklı genişletilmiş ASCII kümeleri çıkarılmıştır. Bu farklı kümelere kod sayfası da denmektedir.
Ancak genişletilmiş ASCII sistemi de sorunu kökten çözmeyi başaramamıştır. Genişletilmiş ASCII'nin eksiklikleri şu iki maddeyle özetlenebilir:
- Farklı dillere özgü çoğu karakterin aynı metin içinde kullanılamaması
- İçinde binlerce farklı karakter bulunduran Çin Japon Kore dillerinin alfabelerini temsilde 256 karakterin yetersiz kalması
Birbirinden farklı ASCII kümelerinde bulunan dillerin karakterlerinin aynı metinde bulunması mümkün değildir. Çünkü 128 ve sonrasındaki sayılar her genişletilmiş ASCII kümesinde farklı karakterlere karşılık gelebilmektedirler. Eğer belgedeki kodlamanın hangi kod sayfasına göre yapıldığı belirtilmemişse metnin doğru okunması mümkün olmamaktadır. Örneğin İnternet üzerinde kodlama türünün belirtilmemiş olması veya yanlış belirtilmiş olması nedeniyle Türkçe karakterlerden ı, ş karakterlerinin ý, þ olarak görünmesinin nedeni Türkçe için üretilmiş olan Latin-5 kod sayfasında bu karakterlere karşılık gelen sayıların, İnternet tarayıcılarının kodlama türü belirtilmediğinde varsayılan olarak kullandığı Latin-1 kodlamasında İzlanda alfabesinden ý, þ karakterlerine karşılık gelmesi yüzündendir. Dolayısıyla diğer dillerin alfabeleri için bir çözüm olarak öne sürülen genişletilmiş ASCII sistemi de tam çözüm olamamıştır.
Farklı kod sayfaları arasında karışıklığa yol açması bir yana içinde binlerce farklı karakter barındıran Çince veya Japonca gibi dillerin harfleri için fazladan gelen 128 karakterlik kapasitenin de yeterli olması olanaksızdır. Bu yüzden ASCII sistemi yerini Unicode'a bırakmıştır. Ancak yine de yıllardan beri kullanılmış olması nedeniyle bu kodlamayla üretilmiş birçok yazılım, web sayfası bulunmaktadır. Unicode sistemi teşvik edilse de işletim sistemleri eski yazılım ve web sayfaları nedeniyle ASCII kodlamasını da Unicode ile birlikte hâlâ mecburen desteklemektedir.
Ortaya çıkışı
Unicode'un kökeni 1987'ye dek uzanmaktadır. Bu tarihte Xerox çalışanı Joe Becker ve Apple çalışanı Mark Davis evrensel bir karakter kümesi oluşturmanın sağlayacağı faydalar üzerinde çalışma yapmaktaydı.[3] Ağustos 1988 tarihinde, Joe Becker "şimdilik Unicode olarak adlandırılan uluslararası/çokdilli metin karakteri kodlama sistemi" için bir teklif taslağı hazırladı. Unicode ismini eşsiz, tek ve evrensel bir kodlama sistemini çağrıştırması amacıyla seçtiğini belirtmiştir.[4]
Unicode 88 başlıklı belgede Becker 16-bitlik bir karakter modeli taslağı hazırlamıştır:[4]
Unicode, güvenilir ve üzerinde çalışılabilir dünya geneli bir metin kodlaması ihtiyacına cevap verme niyetiyle ortaya çıkmıştır. Unicode kabaca, dünyadaki bütün yaşayan dillerin tüm karakterlerini kapsayabilmesi amacıyla uzunluğu 16 bite çıkarılmış "geniş gövdeli bir ASCII" olarak tanımlanabilir. Mühendisliği düzgünce yapılan bir tasarımla, karakter başına 16 bit bu amaç için fazlasıyla yeterli olacaktır.
Orijinal 16-bitlik tasarım sadece günlük kullanıma dahil olan karakterlerin ve yazı türlerinin kodlanmasına ihtiyaç duyulacağını varsaymasından kaynaklanıyordu:[4]
Unicode eskiden beri gelenleri korumaktansa geleceğe dönük yararlılığı garanti altına almayı yüksek öncelik edinmiştir. Unicode ilk olarak çağdaş metinlerde kullanılan karakterleri (yani 1988 yılında dünyada basılan gazete ve dergilerin kullandığı karakterlerin tümünü) hedeflemektedir ki bu karakterlerin sayısı şüphesiz 214 = 16.384'ü geçmez. Çağdaş kullanım dahilinde olan karakterlerin dışında kalan diğer karakterlerin eskimiş olduğu veya ender kullanıldığı kabul edilebilir. Çoğunlukla kullanışlı karakterleri barındıran Unicode'u bu eski ve nadir karakterlerle kalabalıklaştırmak yerine bu karakterleri özel kullanım kayıtlarına dahil etmek daha iyidir.
1989 yılının başlarında Unicode çalışma grubu Metaphor'dan Ken Whistler ve Mike Kernaghan, Research Libraries Group'tan Karen Smith-Yoshimura ve Joan Aliprand ve Sun Microsystems'tan Glenn Wright da bulunacak şekilde genişletildi. 1990 yılında Microsoft'tan Michel Suignard ve Asmus Freytag ve NeXT'ten Rick McGowan da gruba katıldı. 1990'ın sonlarına doğru mevcut kodlama standartlarındaki karakterlerin eşlenmesi çalışmaları tamamlanmış ve Unicode'un gözden geçirilecek son taslağı hazırlanmıştı.
Unicode Consortium 3 Ocak 1991'de California'da kuruldu. Ekim 1991'de Unicode standardının ilk cildi yayımlandı. Han ideograflarını içeren ikinci cildi de Haziran 1992'de yayımlandı.
1996'da Unicode 2.0'da yedek karakter mekanizması uygulanmaya başladı. Bu sayede Unicode artık 16 bit ile sınırlanmamış oldu. Yedek karakter çiftlerinin kullanılmasıyla Unicode kod alanı bir milyon kod noktasını bulundurarak kadar genişledi. Böylece Unicode, Mısır hiyeroglifleri veya Göktürk alfabesi gibi birçok tarihi yazı sistemlerini ve kodlamasına ihtiyaç duyulmayacağı tahmin edilen, artık kullanılmayan eskimiş karakterleri destekler hale geldi. Unicode tarafından desteklenmesi ilk başta planlanmamış olan karakterler arasında nadiren kullanılan Kanji karakterleri ve Çince karakterler de bulunmaktadır. Bu karakterler artık kullanılmayan kişi veya yer isimlerinin parçası olduklarından nadiren kullanılıyordu ancak orijinal Unicode mimarisinde düşünülenden çok daha önemli karakterlerdir.[5]
Mimari ve terminoloji
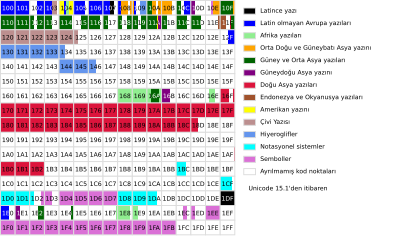
Unicode, 016 ile 10FFFF16 arasındaki sayılara karşılık gelen 1.114.112 adet kod noktasından oluşan bir kod alanı tanımlamıştır.[6] Kod noktası Unicode tarafından her bir karaktere atanan sayıdır ve bu sayı genelde on altı tabanında, hekzadesimal gösterim adı verilen, 10-15 arası rakamların A-F arası harflerle temsil edildiği bir gösterim yöntemiyle yazılır. Normalde Unicode kod noktaları "U+" ve sonrasında kod noktasının on altı tabanındaki karşılığı ile ifade edilir. Kod noktalarının beşinci ve altıncı haneleri birlikte düzlem (plane) numarasını ifade etmektedir, toplamda on yedi adet düzlem bulunmaktadır (016'dan 1016'a kadar). İlk düzlem olan Temel Çokdilli Düzlem (Basic Multilingual Plane, kısaca BMP) sıfırıncı düzlem olduğundan bu düzlemdeki karakterlerin kod noktaları yazılırken beşinci hanedeki 0 yazılmadan dört haneli şekilde yazılırlar (mesela Unicode tanımı latin capital letter x olan X harfinin kod noktası U+000058 yerine kısaca U+0058 olarak ifade edilir), BMP dışındaki düzlemlerde bulunan kod noktaları başında düzlem numarası yazılarak ifade edilir. Dolayısıyla toplamda beş veya altı haneli olarak yazılırlar. (örneğin language tag adlı karakterinin kod noktası U+E0001, Emoji karakterlerinden grinning face adlı 😀 karakterinin kod noktası U+1F600 olarak ifade edilmektedir). Unicode standardının eski sürümlerinde de benzer yazım şekilleri kullanılıyordu ancak ufak farklılıklar bulunmaktaydı. Örneğin Unicode 3.0 standardında kod noktaları yazılırken sekiz haneli kod noktasının önüne "U-" getirilirdi. Kod birimleri yazılırken önüne "U+" konularak yazılırdı.[7]
Kod noktası düzlemleri ve blokları
Unicode kod alanı 0'dan 16'ya kadar numaralanmış on yedi adet düzleme (plane) ayrılmıştır:
| Unicode düzlemleri ve kod noktası aralıkları | ||||||||
|---|---|---|---|---|---|---|---|---|
| Temel Basic | Tamamlayıcı Supplementary | |||||||
| 0. Düzlem | 1. Düzlem | 2. Düzlem | 3–13. Düzlemler | 14. Düzlem | 15–16. Düzlemler | |||
| 0000–FFFF | 10000–1FFFF | 20000–2FFFF | 30000–DFFFF | E0000–EFFFF | F0000–10FFFF | |||
| Temel Çokdilli Düzlem Basic Multilingual Plane | Tamamlayıcı Çokdilli Düzlem Supplementary Multilingual Plane | Tamamlayıcı İdeografik Düzlem Supplementary Ideographic Plane | atanmamış | Tamamlayıcı Özel Amaçlı Düzlem Supplementary Special-purpose Plane | Tamamlayıcı Özel Kullanım Alanı Private Use Area | |||
| BMP | SMP | SIP | — | SSP | S PUA A/B | |||
| 0000–0FFF | 8000–8FFF | 10000–10FFF |
| 20000–20FFF | 28000–28FFF | E0000–E0FFF | 15: PUA-A | |
BMP düzleminde bulunan tüm kod noktaları UTF-16 kodlamasında tek kod birimiyle ve UTF-8 kodlamasında da değişken uzunlukta kod birimleriyle (bir, iki veya üç) kodlanabilir. UTF-16 kodlamasında kod birimleri 16-bit (iki bayta karşılık gelir), UTF-8'de 8-bit (bir bayta karşılık gelir) uzunluğundadır. 1'den 16'ya kadar olan düzlemlerdeki kod noktaları (tamamlayıcı düzlemler, supplementary plane) UTF-8 kodlamasında dört kod birimi ile ve UTF-16'da yedek çiftler veya yer tutucu çiftler (surrogate pairs) denilen bir sistem ile iki kod birimi halinde kodlanırlar.
Her düzlem, blok adı verilen bölümlere ayrılmıştır ve her blokta o blokla ilgili karakterler bulunur. Blokların kapsadığı kod noktalarının sayısı (yani blokların büyüklüğü) değişken olmakla birlikte bu sayı her zaman 16'nın ve genelde de 128'in katıdır. Aynı yazı türünde bulunan karakterler farklı bloklara dağılmış olabilir.
Karakterin Genel Kategorisi
Her kod noktasının Genel Kategori adlı bir niteliği bulunmaktadır. Temel kategoriler şunlardır: Harf (Letter), İm (Mark), Sayı (Number), Noktalama (Punctuation), Sembol (Symbol), Ayırıcı (Seperator) ve Diğer (Other). Bu kategorilerin alt bölümleri de bulunmaktadır. Genel Kategori niteliği her zaman kullanışlı değildir; çünkü eski kodlama sistemleri tek kod noktasına birden fazla özellik yüklemiştir. Örneğin U+000A <control-000A> LINE FEED (SATIR ATLATMA) karakteri ASCII sisteminde hem kontrol hem de düzen ayırıcısı karakteri olarak kullanılmıştır, Unicode'da bu karakterin Genel Kategori niteliği "Diğer, Kontrol" olarak tanımlanmıştır. Bir kod noktasının özelliklerinin ve davranışının tam olarak belirlenebilmesi için diğer niteliklerin de dikkate alınması gerekmektedir. Mevcut Genel Kategoriler şunlardır:
Genel Kategori (Unicode Karakter Niteliği)[a 1]
| |||||
|---|---|---|---|---|---|
| Değer | Büyük, küçük kategoriler | Temel tür[a 2] | Atanmış karakter[a 2] | Sabit[a 3] | Yorumlar |
| 000Harf (Letter) | |||||
| 001Lu | Harf, büyük harf | Çizgesel (Graphic) | Var | ||
| 002Ll | Harf, küçük harf | Çizgesel | Var | ||
| 003Lt | Harf, ilk harf büyük | Çizgesel | Var | Büyük ve küçük harflerden oluşan bağlı harfler (Dž, Lj, Nj, ve Dz gibi) | |
| 004Lm | Harf, niteleyici | Çizgesel | Var | ||
| 005Lo | Harf, diğer | Çizgesel | Var | ||
| 010İm (Mark) | |||||
| 011Mn | İm, boşluksuz | Çizgesel | Var | ||
| 012Mc | İm, boşluklu birleşen | Çizgesel | Var | ||
| 013Me | İm, çevreleyen | Çizgesel | Var | ||
| 020Sayı (Number) | |||||
| 021Nd | Sayı, onluk rakam | Çizgesel | Var | Sadece bu kategorideki karakterler Sayısal Tür = De niteliğine sahiptir[a 3] | |
| 022Nl | Sayı, harf | Çizgesel | Var | Harflerden veya harf benzeri karakterlerden oluşan sayılar (mesela Roma rakamları) | |
| 023No | Sayı, diğer | Çizgesel | Var | Basit kesirler, üst simge veya alt simge şeklinde yazılan rakamlar | |
| 030Noktalama (Punctuation) | |||||
| 031Pc | Noktalama, bağlayıcı | Çizgesel | Var | "_" alt çizgi karakterini içerir | |
| 032Pd | Noktalama, tire | Çizgesel | Var | Birçok tire imi karakterlerini içerir | |
| 033Ps | Noktalama, açan | Çizgesel | Var | Açan ayraç karakterleri | |
| 034Pe | Noktalama, kapatan | Çizgesel | Var | Kapatan ayraç karakterleri | |
| 035Pi | Noktalama, açan tırnak | Çizgesel | Var | Açan tırnak işareti. ASCII "nötr" tırnak işaretini içermez. Kullanıma bağlı olarak Ps veya Pe olarak davranır | |
| 036Pf | Noktalama, kapatan tırnak | Çizgesel | Var | Kapatan tırnak işareti. Kullanıma bağlı olarak Ps veya Pe olarak davranır | |
| 037Po | Noktalama, diğer | Çizgesel | Var | ||
| 040Sembol (Symbol) | |||||
| 041Sm | Sembol, matematik | Çizgesel | Var | ||
| 042Sc | Sembol, para birimi | Çizgesel | Var | ||
| 043Sk | Sembol, niteleyici | Çizgesel | Var | ||
| 044So | Sembol, diğer | Çizgesel | Var | ||
| 050Ayırıcı (Seperator) | |||||
| 051Zs | Ayırıcı, boşluk | Çizgesel | Var | Boşluk karakterini, SEKME (TAB), satır başı ve satır atlatma gibi Cc karakterlerini içerir | |
| 052Zl | Ayırıcı, satır | Biçimlendirme | Var | Sadece U+2028 LINE SEPARATOR (SATIR AYIRICISI) ({{{no}}}) | |
| 053Zp | Ayırıcı, paragraf | Biçimlendirme | Var | SadeceU+2029 PARAGRAPH SEPARATOR (PARAGRAF AYIRICISI) ({{{no}}}) | |
| 060Diğer (Other) | |||||
| 061Cc | Diğer, kontrol | Kontrol | Var | Sabit 65 | Adsız[a 4], <control> |
| 062Cf | Diğer, biçimlendirme | Biçimlendirme | Var | Satır sonu çizgisini, çift yönlü metinleri desteklemek için gereken kontrol karakterlerini ve dil etiketi karakterlerini içerir | |
| 063Cs | Diğer, yedek | Yedek | Yok (soyut) | Sabit 2048 | Adsız[a 4], <surrogate> |
| 064Co | Diğer, özel kullanım | Özel kullanım | Yok (soyut) | Sabit BMP'de 6.400, 15–16. Düzlemlerde 131.068 tane | Adsız[a 4], <private-use> |
| 065Cn | Diğer, atanmamış | Yok | Yok | Sabit 66 | Adsız[a 4], <noncharacter> |
| Ayrılmış (Reserved) | Yok | Sabit değil | Adsız[a 4], <reserved> | ||
| |||||
U+D800..U+DBFF aralığında bulunan 1.024 kod noktası üst yedek kod noktaları olarak ve U+DC00..U+DFFF aralığında 1.024 kod noktası da alt yedek kod noktaları olarak bilinir. Üst yedek kod noktası (veya öndeki kod noktası) ve sonrasında gelen alt kod noktasının (veya arkadaki kod noktası) oluşturduğu çifte yedek çifti denir bu yedek çiftleri UTF-16 kodlaması tarafından BMP'nin dışında kalan kod noktalarını kodlamak için kullanılır. UTF-16 kodlaması kod noktalarını iki bayttan oluşan birimler halinde kodlamaktadır, iki bayt ile kodlanabilecek en büyük sayı FFFF16 (6553510) olduğundan U+FFFF'nin sonrasındaki kod noktalarını ifade etmek için U+D800'den U+DFFF'ye kadar olan kod noktaları Unicode tarafından yedek kod noktaları olarak kullanılmak üzere ayrılmıştır. Bu kod noktaları çiftler halinde kullanılarak BMP dışında kalan 1.048.560 karakteri UTF-16 ile kodlamaya fazlasıyla yetmektedir (1.024 * 1.024 = 1.048.576 adet yedek çifti kombinasyonu vardır). Üst ve alt yedek kod noktaları tek başlarına anlamsız ve geçersizdir. Çiftler halinde kullanıldıkları zaman bir karakteri temsil ederler. Dolayısıyla, yedek çifti olarak kullanılmak üzere ayrılmış olan U+D800..U+DFFF aralığındaki kod noktaları U+10000..U+10FFFF aralığındaki kod noktalarının yerini tutmak amacıyla kullanıldığından, karakter olarak kullanılabilecek kod noktaları yedek kod noktaları dışında kalan kod noktalarıdır (U+0000..U+D7FF ve U+E000..U+10FFFF aralığında kalan 1.112.064 kod noktası). Karakter olarak kullanılabilecek kod noktalarına aynı zamanda karakterin skaler değeri de denmektedir. Örneğin UTF-16'da yedek çiftleri kullanılarak (D803 DC00)16 olarak kodlanan U+10C00 𐰀 OLD TURKIC LETTER ORKHON A karakterinin skaler değeri U+10C00'dır denir. Çünkü (D803 DC00)16 yedek çifti 10C0016 sayısını temsil eder.
Unicode bazı kod noktalarına ne şimdi ne de gelecekte herhangi bir karakter atamayacağını duyurmuştur. Karakter dışı kod noktaları Unicode şartnamesinde noncharacter olarak adlandırılmaktadır. Karakter dışı kod noktaları yazılımların iç yapısında herhangi bir amaçla kullanılabilir. Toplamda 66 adet karakter dışı kod noktası bulunmaktadır. U+FDD0..U+FDEF aralığındaki kod noktaları ve her düzlemin son iki kod noktası (yani U+FFFE, U+FFFF, U+1FFFE, U+1FFFF, ... U+10FFFE, U+10FFFF). Karakter dışı kod noktaları sabittir, ileride yeni karakter dışı kod noktası tanımlanmayacaktır.[8]
Ayırtılmış (reserved) kod noktaları da ileride kodlama karakteri olarak kullanılacak olan ama henüz Unicode tarafından kendilerine karakter atanmamış kod noktalarıdır.
Özel kullanım kod noktaları da karakter olarak kullanılabileceği belirtilen ancak hangi karakteri temsilen kullanılacakları Unicode tarafından belirtilmeyip kullanıcıya bırakılmış olan karakterlerdir[9]. Yani bu karakterler yazılı bilgi alışverişi esnasında taraflar arasında önceden yapılmış bir anlaşamaya göre yorumlanabilecek karakterlerdir. Unicode kod alanında üç adet özel kullanım bölgesi vardır:
- Özel Kullanım Alanı: U+E000..U+F8FF (6.400 karakter)
- Tamamlayıcı Özel Kullanım Alanı-A: U+F0000..U+FFFFD (65.534 karakter)
- Tamamlayıcı Özel Kullanım Alanı-B: U+100000..U+10FFFD (65.534 karakter).
Çizgesel karakterler (graphic characters), Unicode tarafından tanımlanan, belirli bir anlamsal değeri olan ve görünür bir glif şekline sahip veya görünür bir boşluğu temsil eden karakterlerdir. Unicode 7.0 itibarıyla 112.804 çizgesel karakter vardır.
Biçimlendirme karakterleri ise görünür bir şekilleri olmayan ancak komşu karakterlerin görünüşünü veya davranışını etkileyen karakterlerdir. Örneğin U+200C ZERO WIDTH NON-JOINER karakteri ve U+200D ZERO WIDTH JOINER karakteri bitişebilen karakterlerin bitişme durumunu belirlemek için kullanılabilir. Unicode 7.0'da 152 biçimlendirme karakteri bulunmaktadır. Başka bir örnek vermek gerekirse metin dosyalarında bilgisayarlarda ↵ Enter tuşuna basarak yapılan alt satıra geçme işlemi sırasında metne U+000A <control-000A> ({{{no}}}) ve U+000D <control-000D> ({{{no}}}) karakterleri işlenir, bu karakterler metin üzerinde görünür bir yer kaplamadığı halde kendilerinden sonra gelen karakterlerin alt satırda görüntülenmesini sağladıkları için kontrol işlevi görür ve çizgesel karakter sınıfına girmez.
Altmış altı kod noktası (U+0000..U+001F ve U+007F.. U+009F aralıkları) kontrol kodları olarak ayrılmıştır ve ISO/IEC 6429 standardıyla belirlenen C0 ve C1 kontrol kodlarına karşılık gelir. Unicode'la uyumlu kodlamalarda bu kontrol karakterlerinden U+0009 <control-0009> ({{{no}}}), U+000A <control-000A> ({{{no}}}) ve U+000D <control-000D> ({{{no}}}) karakterleri sıklıkla kullanılır.
Çizgesel karakterler, biçimlendirme karakterleri ve kontrol kodu karakterleri hep beraber atanmış karakterler olarak bilinir.
Soyut karakterler
Soyut karakter, metinsel bir verinin düzenlenmesi, denetlenmesi veya temsil edilmesi için kullanılan bilgi birimi olarak tanımlanmıştır. Soyut karakterin bir kod noktasıyla eşleştirilmiş haline kodlu karakter denir ve kodlu karakterler genelde kısaca karakter olarak anılır. Soyut karakterler, karakterlerin temsil ettikleri bilginin soyut, yani şekil almamış halini temsil eder. Unicode standardında tek bir kod noktasıyla ifade edilebilen bir soyut karakter aynı zamanda birden fazla kod noktasının yan yana kullanılmasıyla da alternatif olarak temsil edilebilir.[10] Örneğin â harfi, Unicode tanımı U+00E2 â LATIN SMALL LETTER A WITH CIRCUMFLEX kod noktasıyla ifade edilebileceği gibi U+0061 a LATIN SMALL LETTER A ve U+0302 ̂ COMBINING CIRCUMFLEX ACCENT kod noktalarının yan yana kullanılmasıyla da ifade edilebilir. İki farklı şekilde de aynı görüntü ortaya çıkacaktır: U+00E2 â ve U+0061 U+0302 â. Bu karakterler kodlamaları itibarıyla farklı olmalarına rağmen aynı soyut karakteri temsil etmektedir. Birisi tek bir kod noktasından oluşurken diğeri harfin parçalarına karşılık gelen kod noktalarının birleştirilmesiyle ifade edilir. Ancak bazı soyut karakterlerin Unicode standardında tek kod noktasıyla karşılığı yoktur. Bu yüzden bu soyut karakterler birden fazla kod noktasının art arda kullanılmasıyla ifade edilebilirler. Unicode yalnızca iki kod noktasının kombinasyonuyla ifade edilebilen soyut karakterlerin bir listesini sitesinde barındırmaktadır.[11]
Ayrıca, diğer standartlarla uyumluluk sağlamak için bazen aynı soyut karakter birden çok tekil kodlanmış karaktere karşılık gelebilir. Bu durum aynı karakterin birden fazla kod noktasının birleşimi şeklinde gösterilmesinden farklıdır. Mesela Å karakteri Unicode standardında U+00C5 Å LATIN CAPITAL LETTER A WITH RING ABOVE kod noktasıyla temsil edilmektedir. Ancak aynı soyut karakteri temsil eden U+212B Å ANGSTROM SIGN adlı bir kod noktası da bulunmaktadır.
Tüm çizgesel karakterler, biçimlendirme karakterleri ve özel kullanım karakterlerinin eşsiz ve değişmez bir tanımlayıcı adı vardır. İsimlerin değişmezliği Unicode sürüm 2.0'dan itibaren İsim Kararlılığı Politikası ile garanti altına alınmıştır [8]. Tanımlayıcı adın ciddi derecede sorunlu ve yanıltıcı olduğu veya önemli yazım hataları içerdiği durumlarda resmi bir ikincil ad tanımlanabilir ve uygulamaların resmi karakter adı yerine resmi ikincil adı kullanmaları tavsiye edilir. Örneğin Yi yazısına ait karakterlerden yanlış adlandırılan U+A015 ꀕ YI SYLLABLE WU karakterine daha sonra yi syllable iteration mark (yi hece yineleme işareti) şeklinde ikincil bir ad tanımlanmıştır. U+FE18 ︘ PRESENTATION FORM FOR VERTICAL RIGHT WHITE LENTICULAR BRAKCET ({{{no}}}) karakteri daha sonra ikincil ad olarak presentation form for vertical right white lenticular bracket adını almıştır.[12]
Karakter kodlamaları
Eskiden karakter kodlaması kavramı hem her karaktere birer sayı atama hem de bu sayıları doğrudan iki tabanına dönüştürüp bilgisayarda kullanılabilir hale getirme işlemine verilen isimdi. Bu yüzden Unicode'dan önce kullanılan ASCII ve tüm genişletilmiş ASCII sistemleri birer karakter kodlamasıdır. Unicode'dan sonra ise karakter kodlaması kavramı değişmiştir. Unicode, karakterlere sayı atanmasıyla bu sayıların iki tabanına dönüştürülmesi işlemini birbirinden ayırmıştır. Çünkü Unicode ile beraber karakterlere atanan sayıları (kod noktalarını) doğrudan iki tabanına dönüştürmektense farklı yöntemler kullanarak dönüştürme ihtiyacı ortaya çıkmıştır. Dolayısıyla Unicode'dan sonra karakter kodlaması kavramı kod noktalarını iki tabanında temsil etme yöntemini karşılar olmuştur.
Tanımda meydana gelen bu değişikliğin nedeni, Unicode'un genişletilmiş ASCII kümelerinin karakterlere atamak için kullandığı [0, 255] olan sayı aralığını [0, 1.114.111]'e çıkarmasında yatmaktadır. Unicode'dan önceki sistemlerde karakterlere atanan sayılar 255'i aşmadığı için, bu sayılar doğrudan iki tabanına çevrilip karakterleri temsil etmek için kullanılabiliyordu. Örneğin ASCII sistemlerinde a harfi 9710 sayısıyla eşleştirilmişti ve herhangi bir metin belgesinde a harfi kodlanacağı zaman 9710 iki tabanına dönüştürülüp 11000012 şeklinde 8-bitlik bir bayt olarak depolanıyordu. Sayılar 255'i aşmadığı için her karakter 1 bayta sığmaktaydı. Ancak Unicode sisteminde 255'ten büyük sayılar iki tabanında 8 biti aşmaktadır ve eğer 1.114.111 sayının hepsi eşit uzunlukta olacak şekilde doğrudan iki tabanına dönüştürülüp kullanılmak istenirse her karakterin 32 bit uzunluğunda olması, iki tabanına dönüştürüldüğünde 32 bitten kısa olan sayıların da başına sıfır eklenerek 32 bite tamamlanması gerekir. Çünkü her karakterin uzunluğu sabit olmazsa kodlamada bir karakterin nerede bitip diğerinin nerede başladığı anlaşılamaz. Bu durum genişletilmiş ASCII'ye göre kodlanmış bir metne göre Unicode ile kodlanmış bir metnin dört kat kadar fazla yer kaplamasına neden olacaktır.
Her karakterin eşit uzunlukta bitlerle temsil edilmesi zorunluluğundan kurtulmak istenirse karakterlerin kod noktalarını iki tabanına dönüştürürken araya karakterin başlangıcını veya sonunu belli edecek işaretler eklenerek kodlama yapılması gerekecektir. Bu işlem için geliştirilen birkaç farklı kodlama sistemi bulunmaktadır. Bunlara örnek olarak UTF-8, UTF-16 ve UTF-32 gösterilebilir. Bunların her biri, karakterlerin kod noktalarını (yani Unicode tarafından kendilerine atanan sayıları) bilgisayar ortamında saklamak ve üzerinde işlem yapmak amacıyla iki tabanına dönüştürürken farklı yöntemler kullanırlar. Her birinin farklı avantajları ve dezavantajları mevcuttur. Günümüzde en yaygın kullanılan kodlama UTF-8 kodlamasıdır.
Dış bağlantılar
- Unicode Consortium5 Şubat 2005 tarihinde Wayback Machine sitesinde arşivlendi.
- Standardlar
- RFC 3629
- RFC 3492
- Unicode karakterleri topluca bulabileceğiniz bir site. 5 Aralık 2008 tarihinde Wayback Machine sitesinde arşivlendi.
- Emojiler ve Unicode'ları 28 Mayıs 2019 tarihinde Wayback Machine sitesinde arşivlendi.
Ayrıca bakınız
Kaynakça
- ^ "The Unicode Standard: A Technical Introduction (Unicode Standardı: Teknik Tanıtım)" (İngilizce). 31 Aralık 2015 tarihinde kaynağından arşivlendi. Erişim tarihi: 16 Mart 2010.
- ^ "Unicode 8.0.0, Summary" (İngilizce). 28 Haziran 2016 tarihinde kaynağından arşivlendi. Erişim tarihi: 6 Temmuz 2015.
- ^ "Özet Hikaye (İngilizce)" (İngilizce). 21 Nisan 2016 tarihinde kaynağından arşivlendi. Erişim tarihi: 15 Mart 2010.
- ^ a b c Joseph D. Becker (29 Ağustos 1988). "Unicode 88" (PDF) (İngilizce). 28 Mayıs 2016 tarihinde kaynağından arşivlendi (PDF). Erişim tarihi: 20 Temmuz 2014.
- ^ Stephen J Searle. "Unicode Revisited". 8 Nisan 2016 tarihinde kaynağından arşivlendi. Erişim tarihi: 18 Ocak 2013.
- ^ "Unicode terimleri sözlüğü" (İngilizce). 26 Aralık 2015 tarihinde kaynağından arşivlendi. Erişim tarihi: 16 Mart 2010.
- ^ "Unicode Standardı, Sürüm 6.0, s. 62, Karakter Kodlama Biçimleri" (PDF) (İngilizce). 8 Ağustos 2012 tarihinde kaynağından arşivlendi (PDF). Erişim tarihi: 4 Haziran 2012.
- ^ a b "Unicode Karakter Kodlaması Kararlılık Politikası" (İngilizce). 10 Nisan 2016 tarihinde kaynağından arşivlendi. Erişim tarihi: 16 Mart 2010.
- ^ "Nitelikler" (PDF) (İngilizce). 7 Nisan 2010 tarihinde kaynağından arşivlendi (PDF). Erişim tarihi: 16 Mart 2010.
- ^ "Unicode Karakter Kodlama Modeli" (İngilizce). 15 Aralık 2015 tarihinde kaynağından arşivlendi. Erişim tarihi: 16 Mart 2010.
- ^ "Unicode Adlandırılmış Dizilimler" (İngilizce). 27 Kasım 2015 tarihinde kaynağından arşivlendi. Erişim tarihi: 16 Mart 2010.
- ^ "Unicodeİkincil Adlar" (İngilizce). 28 Mayıs 2016 tarihinde kaynağından arşivlendi. Erişim tarihi: 16 Mart 2010.










