Processo de Gram-Schmidt

Em matemática e análise numérica, o processo de Gram-Schmidt é um método para ortonormalização de um conjunto de vetores em um espaço com produto interno, normalmente o espaço euclidiano Rn. O processo de Gram–Schmidt recebe um conjunto finito, linearmente independente de vetores S = {v1, …, vn} e retorna um conjunto ortonormal S' = {u1, …, un} que gera o mesmo subespaço S inicial.
O método leva o nome de Jørgen Pedersen Gram e Erhard Schmidt, mas pode ser encontrado antes nos trabalhos de Laplace e Cauchy. Em teoria de decomposição do grupo de Lie é generalizado pela decomposição de Iwasawa.[1]
A aplicação do processo de Gram-Schmidt aos vetores de uma coluna matricial completa de classificação produz a fatoração QR (decomposta numa matriz ortogonal e uma matriz triangular).
O processo de Gram-Schmidt
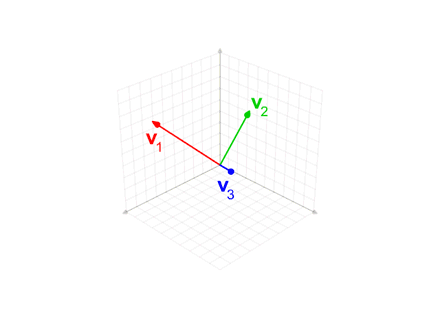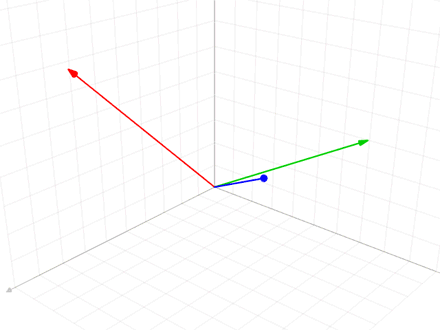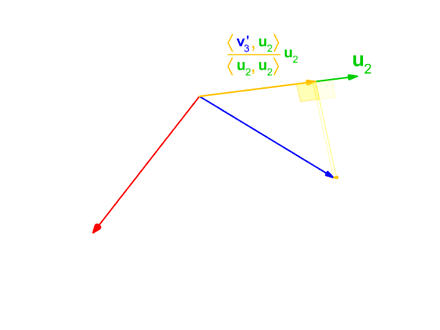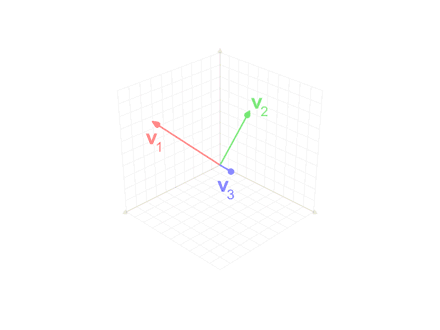
Define-se o operador projeção por:

no qual denota o produto interno dos vetores v e u. Esse operador projeta o vetor v ortogonalmente sobre a linha gerada pelo vetor u. Se u=0, define-se . i.e., o mapa projetado é o mapa zero, enviando cada vetor ao vetor zero.



O processo de Gram-Schmidt funciona então como denotado abaixo:

A sequência u1, ..., uk é o sistema de vetores ortogonais requerido, e o vetores normalizados e1, ..., ek formam um conjunto ortonormal. O cálculo da sequência u1, ..., uk é conhecido como ortogonalização Gram–Schmidt,enquanto o cálculo da sequência e1, ..., ek é conhecido como ortonormalização Gram–Schmidt, à medida que os vetores estão normalizados.
Para verificar se essas fórmulas produzem uma sequência ortogonal, primeiro calcule ‹ u1,u2 ›substituindo a fórmula acima por u2: obtém-se zero. Então proceda para o cálculo de ‹ u1,u3 › novamente substituindo a fórmula por u3: obtém-se mais uma vez zero. A prova geral procede por indução matemática.
Geometricamente, esse método se segue como: para calcular ui, projeta-se vi ortogonalmente sobre o subespaço U gerado por u1, ..., ui−1, que é o mesmo que o subespaço gerado por v1, ..., vi−1. O vetor ui então é definido como a diferença entre vi e essa projeção, garantido como ortogonal para todos os vetores no subespaço U.
O processo de Gram-Schmidt também se aplica a uma sequência de conjunto contável linear e independente {vi}i. O resultado é uma sequência ortogonal (ou ortonormal) {ui}i tal para número natural n: a extensão de algébrica v1, ..., vn é a mesma de que u1, ..., un.
Se o processo de Gram-Schmidt é aplicado a uma sequência linearmente dependente, ele emite 0 vetor em ith etapa, assumindo que vi é a combinação linear de v1, ..., vi−1. Se uma base ortonormal está a ser produzida, então o algoritmo deve testar para zero vetores na saída (output) e descartá-los porque nenhum múltiplo de um vetor zero pode ter um comprimento de valor 1. O número de vetores de saída dados pelo algoritmo será então a dimensão do espaço gerado pelos inputs originais.
Uma variante do processo de Gram-Schmidt utilizando indução transfinita aplicada a uma sequência infinita de vetores (possivelmente incontável) produz um conjunto de vetores ortonormais com de tal modo que qualquer , o complemento do espaço de é o mesmo que . Particularmente, quando aplicado a uma base (algébrica) de um espaço de Hilbert (ou, mais geralmente, uma base de qualquer subespaço denso), produz-se uma base ortonormal (analítica-funcional). Note-se que, no caso geral, muitas vezes a desigualdade estrita preserva, mesmo que o conjunto inicial for linearmente independente, e o espaço de não precisa ser um subespaço do espaço de (pelo contrário, é um subespaço de sua conclusão).







Exemplo
Considerado o seguinte conjunto de vetores em R2 (com o produto interno convencional)

Então, proceda Gram–Schmidt, a fim de obter um conjunto ortogonal de vetores:


Verifica-se que os vetores u1 e u2 são de fato ortogonais:

notando que, se o produto escalar de dois vetores for 0 , então eles serão ortogonais.
Para vetores diferentes de zero, pode-se normalizar os vetores dividindo seu tamanhos como mostrado acima:


Estabilidade numérica
Quando esse processo é executado em um computador, os vetores muitas vezes não são muito ortogonais, devido a erros de arredondamento. Para o processo de Gram-Schmidt, tal como descrito acima, (podendo ser referenciado eventualmente como "processo de Gram-Schmidt clássico") tal perda de ortogonalidade é algo particularmente ruim; Portanto, diz-se que o processo (clássico) de Gram-Schmidt é numericamente instável.

O processo de Gram-Schmidt pode ser estabilizado por meio de uma pequena modificação; tal versão do processo é por vezes referida como processo Gram-Schmidt modificado. Tal abordagem dá o mesmo resultado que a fórmula original numa aritmética exata e introduz erros menores na aritmética de finita-precisão. Ao invés de calcular o vetor uk como

ele é calculado como

Cada passo encontra um vetor ortogonal a . Assim também é ortogonalizado contra quaisquer erros introduzidos no cálculo de .


Este método é utilizado na animação anterior, quando o vetor intermediário v'3 é usado na ortogonalização do vetor azul v3.
Algoritmo
O algoritmo a seguir implementa a ortonormalização Gram-Schmidt estabilizada. Os vetores v1, ..., vk são substituídos por vetores ortonormais que abrangem o mesmo subespaço.

O custo desse algoritmo é assintoticamente 2nk2 operações de ponto flutuante, nas quais n é a dimensionalidade dos vetores (Golub & Van Loan 1996, §5.2.8).
Fórmula determinante
O resultado do processo de Gram-Schmidt pode ser expresso em uma fórmula não-recursiva usando determinantes.


na qual D 0=1 e, para j ≥ 1, D j é o determinante Gram

Note que a expressão para uk é um determinante "formal", i.e. a matriz contém ambos os escalares e vetores; o significado dessa expressão é definido como sendo o resultado de um cofator de expansão ao longo da linha de vetores.
A fórmula determinante de Gram-Schmidt é computacionalmente mais lenta (exponencialmente mais lenta) do que os algoritmos recursivos descritos acima; é principalmente de interesse teórico.
Alternativas
Outros algoritmos de ortogonalização utilizam a transformação de Householder ou a rotação de Givens. Os algoritmos que utilizam a transformação de Householder são mais estáveis que o processo de Gram–Schmidt estabilizado. Por outro lado, o referido processo produz o th vetor ortogonalizado baseado na interação th, enquanto a ortogonalização utilizando a reflexão Householder produz todos os vetores apenas no final. Isso torno o processo de Gram–Schmidt aplicável ao método iterativo assim como a iteração Arnoldi.

Outra alternativa é motivada ainda pelo uso da decomposição de Cholesky para invertendo a matriz das equações normais de mínimos quadrados lineares. Tome-se a estar num posto coluna cheia de uma matriz, cujas colunas precisam ser ortogonalizadas. A matriz é uma matriz transposta conjugada e definida positiva, de tal modo que possa ser escrita utilizando a decomposição de Cholesky. A matriz triangular inferior com entradas diagonais estritamente positivas é inversa. As colunas da matriz são ortonormais e abrangem o mesmo subespaço como as colunas da matriz original . O uso explícito do conteúdo torna o algoritmo instável, espacialmente se o produto do número de condicionamento for elevado. No entanto, esse algoritmo é utilizado na prática e implementado em alguns pacotes de software por conta de sua alta eficiência e simplicidade.





Em mecânica quântica existem vários esquemas de ortogonalização com características mais adequadas para certas aplicações do que os de Gram-Schmidt. No entanto, o Gram-Schmidt continua a ser um algoritmo popular e eficaz, mesmo para os maiores cálculos de estrutura eletrônica.[2]
Referências
Leituras adicionais
- Bau III, David; Trefethen, Lloyd N. (1997), Numerical linear algebra, ISBN 978-0-89871-361-9, Philadelphia: Society for Industrial and Applied Mathematics .
- Golub, Gene H.; Van Loan, Charles F. (1996), Matrix Computations, ISBN 978-0-8018-5414-9 3rd ed. , Johns Hopkins .
- Greub, Werner (1975), Linear Algebra 4th ed. , Springer .
- Soliverez, C. E.; Gagliano, E. (1985), «Orthonormalization on the plane: a geometric approach» (PDF), Mex. J. Phys., 31 (4): 743-758 .
Ligações externas
 Portal da matemática
Portal da matemática

- Hazewinkel, Michiel, ed. (2001), «Orthogonalization», Enciclopédia de Matemática, ISBN 978-1-55608-010-4 (em inglês), Springer
- Harvey Mudd College Math Tutorial on the Gram-Schmidt algorithm
- Earliest known uses of some of the words of mathematics: G The entry "Gram-Schmidt orthogonalization" has some information and references on the origins of the method.
- Demonstrações: Gram Schmidt process in plane e Gram Schmidt process in space
- Gram-Schmidt orthogonalization applet
- NAG Gram–Schmidt orthogonalization of n vectors of order m routine
- Prova: Raymond Puzio, Keenan Kidwell. "proof of Gram-Schmidt orthogonalization algorithm" (version 8). PlanetMath.org.









