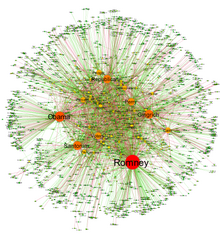
Narrative Network of US Election 2012 - Nodes indicate noun phrases, links go from subject to object, color expresses relation of support or opposition. Appeared in: "Automated analysis of the US presidential elections using Big Data and network analysis; S Sudhahar, GA Veltri, N Cristianini; Big Data & Society 2 (1), 1-28, 2015"
Penambangan teks (bahasa Inggris: text mining) adalah proses ekstraksi pola berupa informasi dan pengetahuan yang berguna dari sejumlah besar sumber data teks, seperti dokumen Word, PDF, kutipan teks, dll. Jenis masukan untuk penambangan teks ini disebut data tak terstruktur dan merupakan pembeda utama dengan penambangan data yang menggunakan data terstruktur atau basis data sebagai masukan. Penambangan teks dapat dianggap sebagai proses dua tahap yang diawali dengan penerapan struktur terhadap sumber data teks dan dilanjutkan dengan ekstraksi informasi dan pengetahuan yang relevan dari data teks terstruktur ini dengan menggunakan teknik dan alat yang sama dengan penambangan data. Proses yang umum dilakukan oleh penambangan teks di antaranya adalah perangkuman otomatis, kategorisasi dokumen, penggugusan teks, deteksi plagiarisme, dll. (Turban, et.al., 2011)
Rujukan
Berry, M.W.; Kogan, J. (2010). Text Mining: Application and Theory. Chichester: John Wiley & Sons, Ltd.
Feldman, R.; Sanger, J. (2007). The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data. New York: Cambridge University Press.
Turban, E.; et.al. (2011). Decision Support and Business Intelligence Systems (edisi ke-9). New Jersey: Pearson Education, Inc.