Regressionsparameter

Dieser Artikel oder nachfolgende Abschnitt ist nicht hinreichend mit Belegen (beispielsweise Einzelnachweisen) ausgestattet. Angaben ohne ausreichenden Beleg könnten demnächst entfernt werden. Bitte hilf Wikipedia, indem du die Angaben recherchierst und gute Belege einfügst.
Regressionsparameter, auch Regressionskoeffizienten oder Regressionsgewichte genannt, messen den Einfluss einer Variablen in einer Regressionsgleichung.[1] Dazu lässt sich mit Hilfe der Regressionsanalyse der Beitrag einer unabhängigen Variablen (des Regressors) für die Prognose der abhängigen Variablen herleiten.
Bei einer multiplen Regression kann es sinnvoll sein, die standardisierten Regressionskoeffizienten zu betrachten, um die Erklärungs- oder Prognosebeiträge der einzelnen unabhängigen Variablen (unabhängig von den bei der Messung der Variablen gewählten Einheiten) miteinander vergleichen zu können, z. B. um zu sehen, welcher Regressor den größten Beitrag zur Prognose der abhängigen Variablen leistet.
Interpretation des Absolutglieds und der Steigung
Gegeben sei das multiple lineare Modell
- bzw. in Matrixschreibweise .


Den Parameter bezeichnet man als Niveauparameter, Achsenabschnitt, Absolutglied, Regressionskonstante oder kurz Konstante (engl. intercept).

Die Parameter nennt man Steigungsparameter, Steigungskoeffizienten oder Anstieg (engl. slope).

Die sind Störgrößen.

Man unterscheidet bei der Interpretation der Regressionskoeffizienten die folgenden Fälle:
Level-Level-Transformation
Im Fall, bei der die endogene Variable untransformiert (level) ist und die exogene Variable ebenfalls (level) gilt aufgrund von

- .

Damit gilt für den Niveau- und den Steigungsparameter:

und
- , ceteris paribus (c.p.),


Der Niveauparameter lässt sich wie folgt interpretieren: Die Zielgröße beträgt im Mittel (bzw. ) wenn alle Regressoren sind.



Für den jeweiligen Steigungsparameter gilt: Steigt c.p. um eine Einheit, dann steigt im Mittel um -Einheiten.



Log-Log-Transformation
Im Fall, bei der die endogene Variable logarithmisch transformiert (log) ist und die exogene Variable ebenfalls (log) gilt
- , ceteris paribus (c.p.),

Dies kann wie folgt interpretiert werden: Steigt das transformierte c.p. um 1 %, dann steigt das transformierte im Mittel um -Prozent. Ökonomisch würde dies der Interpretation als Elastizität entsprechen.
Standardisierte Regressionskoeffizienten
Die standardisierten Regressionskoeffizienten (gelegentlich auch Beta-Werte oder Beta-Gewicht genannt) ergeben sich aus einer linearen Regression, in der die unabhängigen und abhängigen Variablen standardisiert worden sind, das heißt, der Erwartungswert gleich Null und die Varianz gleich Eins gesetzt wurde. Sie können auch direkt berechnet werden aus den Regressionskoeffizienten der linearen Regression:

- wobei der Regressionskoeffizient für Regressor ,
- Standardabweichung der unabhängigen Variable
- und Standardabweichung der abhängigen Variable




Sind die standardisierten erklärenden Variablen untereinander unabhängig und auch unabhängig vom Störterm (Voraussetzung im klassischen Regressionsmodell), dann gilt



das heißt die Summe der quadrierten standardisierten Regressionskoeffizienten ist kleiner gleich Eins. Sind einer oder mehrere der standardisierten Regressionskoeffizienten größer als Eins bzw. kleiner als minus Eins, weist dies auf Multikollinearität hin.
Beispiel
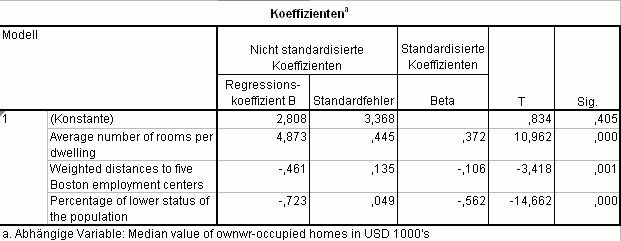
Für die abhängige Variable Mittlerer Hauspreis in selbstbewohnten Häusern pro Bezirk (in 1000 US$) aus dem Boston Housing Datensatz ergibt sich das nebenstehende Regressionsmodell:
- Jedes Zimmer zusätzlich im Haus verteuert den Kaufpreis um 4873 US$,
- jeder Kilometer mehr zu einer Arbeitsstätte reduziert den Kaufpreis um 461 US$ und
- jeder Prozentpunkt mehr beim Anteil der Unterschichtbevölkerung reduziert den Kaufpreis um 723 US$.
Standardisiert man alle Variablen, kann man den Einfluss einer erklärenden Variablen auf die abhängige Variable abschätzen:
- Den größten Einfluss hat die Variable Anteil der Unterschichtbevölkerung: −0,562,
- den zweitgrößten Einfluss hat die Variable Anzahl Zimmer: 0,372 und
- die Variable Entfernung zu Arbeitsstätten hat den geringsten Einfluss: −0,106.
Wären die Variablen unabhängig voneinander, könnte man anhand der quadrierten Regressionskoeffizienten den Anteil der erklärten Varianz angeben:
- Die Variable Anteil der Unterschichtbevölkerung erklärt knapp 32 % der Varianz des mittleren Hauspreises (),
- die Variable Anzahl Zimmer erklärt knapp 14 % der Varianz des mittleren Hauspreises () und
- die Variable Entfernung zu Arbeitsstätten erklärt etwas mehr als 1 % der Varianz des mittleren Hauspreises ().



Literatur
- Jürgen Bortz, Christof Schuster: Statistik für Human- und Sozialwissenschaftler. 7., vollständig überarbeitete und erweiterte Auflage. Springer, Berlin 2010, ISBN 978-3-642-12769-4.
Einzelnachweise
- ↑ Bortz, Schuster: Statistik für Human- und Sozialwissenschaftler. Springer, Berlin / Heidelberg / New York 2010, ISBN 978-3-642-12769-4, S. 342 ff.









